Large Language Models(LLMs) Explained
A deep dive into the technology powering ChatGPT, Bard, and others.



Table of contents
- What are Large Language Models?
- History & Development of Large Language Models
- How do Large Language Models work?
- What are the types of Large Language Models?
- Examples of Large Language Models
- Applications of Large Language Models
- Challenges of Large Language Models
- What is the future of Large Language Models?
Artificial Intelligence (AI) has become one of the hottest topics in conversations and boardroom strategy meetings across the world. Global AI adoption rates have risen astronomically to 35%, which has fueled large investments by major companies, Governments, and record numbers of AI startups positioned to add $15.7 trillion to the global economy by 2030.
This explosion of interest in AI technologies has been propelled in no small way by the advent of different types of Generative AI and their astonishing capabilities, especially Large Language Models (LLMs).
What are Large Language Models?
Large Language Models are deep learning algorithms that have been intensively pre-trained and continuously optimized to recognize, understand, predict, and generate multiple components of text in understandable human language expressions. They are pre-trained (trained) on large amounts (hundreds of millions to trillions) of parameters.
Additionally, they are built to perform other natural language processing(NLP) operations, such as the summarisation and translation of text. LLMs are also utilized alongside other technologies in producing other expressions in image, video, and speech formats.
History & Development of Large Language Models
Large language models are the most advanced types of NLP techniques in use today. The rich development of LLMs has had different turning points over the years.
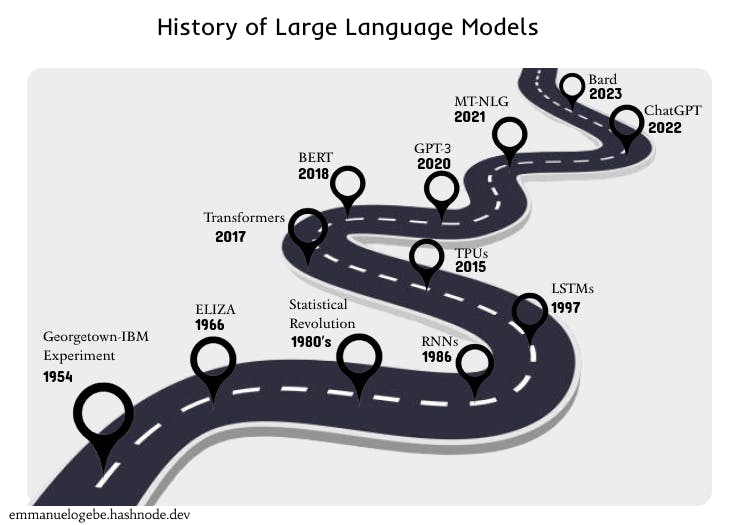
History of Large Language Models [image by author]
In the 1940s, just after the second world war, the push towards global connectedness began, and people realized the need for automatic language translation. Research began, and in 1954, there was a breakthrough as more than sixty Russian sentences were automatically translated into English during the Georgetown-IBM experiment, a joint experiment by Georgetown University academics and IBM staff members.
Moving to 1966, German-American computer scientist and MIT Professor, Joseph Weizenbaum, created the world's first chatbot, ELIZA. Modeled to imitate a therapy session, it could ask open-ended questions and respond according to a set of pre-established instructions. This was the most basic application of what would be known as language models.
A statistical revolution in the 1980s and early 1990s saw the prominent usage of Markov probability processes for predicting future events based on past events. Researchers began depending on the n-gram language model, a Markov process, in determining the next words based on previous words in a given sequence.
The rise of neural networks - computer algorithms inspired by the human brain and their fusion with natural language processing, boosted its capabilities even further. Recurrent Neural Networks (RNNs) introduced in 1986, would mainly be used for this. However, they had a vanishing gradient problem, which impaired their ability to remember the beginning of sentences when carrying analyses of extremely long sentences. This necessitated the launch of Long Short-Term Memory (LSTM) networks in 1997 to improve the accuracy of RNNs.
Into the 21st century, expedited improvements in language processing technologies became prevalent as more private companies championed the effort. Google's creation of the TPU accelerated machine learning functionalities, and the transformer architecture enabled language models to understand context as they could speedily pay attention to the different components of sentence inputs, becoming the game-changer in the development of large language models. BERT, the first breakout large language model, would be introduced and eventually the web interface for Open AI's GPT language model, ChatGPT.
How do Large Language Models work?
Built to keenly imitate the working process of the human brain, especially in perception, cognition, and action, large language models can execute actions based on the data they have been trained on and continues to learn on the go.
Researchers conducting experiments on human brain activity using fMRI scans have confirmed strong relationships between large language model representations and human cognitive processing.
The data is gathered and pre-processed, after which a language model utilizing the data is trained, evaluated, and fine-tuned according to a set of specific guidelines and dependencies. Data sources include books, articles, repositories, and websites such as Wikipedia, Data World, World Bank Open Data, Google Dataset Search, etc. This data can either be categorized or uncategorized.
Working Process
The basic operation of a large language model is for it to predict and or generate the next sequence of words based on a given input.
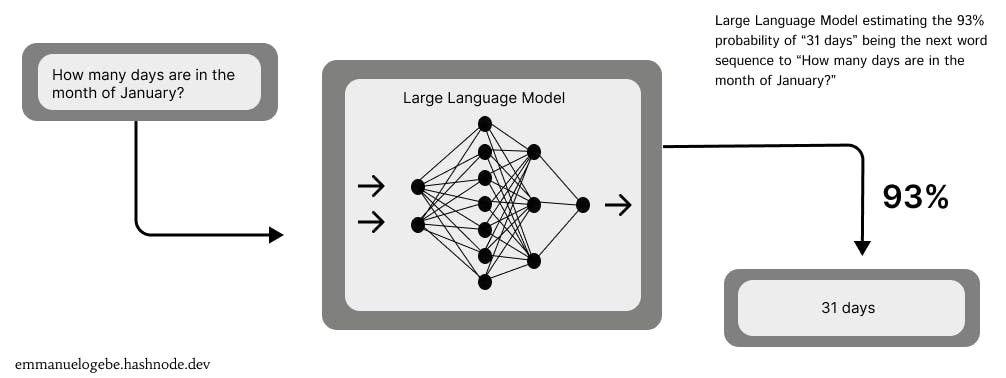
working process of a large language model[image by author]
This is possible through the self-attention mechanism of its transformer-based architecture. When a text input is received, the trained model analyzes it and determines which components (tokens - words, numbers, special characters, symbols, prefixes, suffixes, etc.) of the text are most connected to each other irrespective of their position in the text and then predicts a series of tokens which should follow the input sequence. This process is usually repeated multiple times, to select the most accurate tokens for the sequence as each predicted token is given a probability score and the tokens with the highest scores are fixed.
How are Large Language Models Trained?
When the obtained data has been thoroughly pre-processed, it is tokenized and the model is trained through a self-supervised learning procedure. This procedure enables the model to expeditiously train itself after the guiding parameters have been established to predict tokens. It can also categorize (label) data that was not categorized before the training.
During the training, repeated weight adjustments are made to help reconcile the differences between the actual and predicted words in a sequence. This is done bidirectionally (left-to-right and right-to-left), simulating the human reading process for specific languages, English or Arabic.
After this process, the trained large language model, alternatively termed the foundation model, is evaluated using data it was not trained with, to measure its performance. It can also be upgraded or optimized using different methods (frameworks) for a wide array of use cases.
- Few shot learning method: This framework enables a model pre-trained on a large dataset to be modified using a small labeled dataset to categorize new data (previously unseen by the pre-trained model). It depends on the meta-learning (learning to learn) approach in determining similarity scores for the categorization.
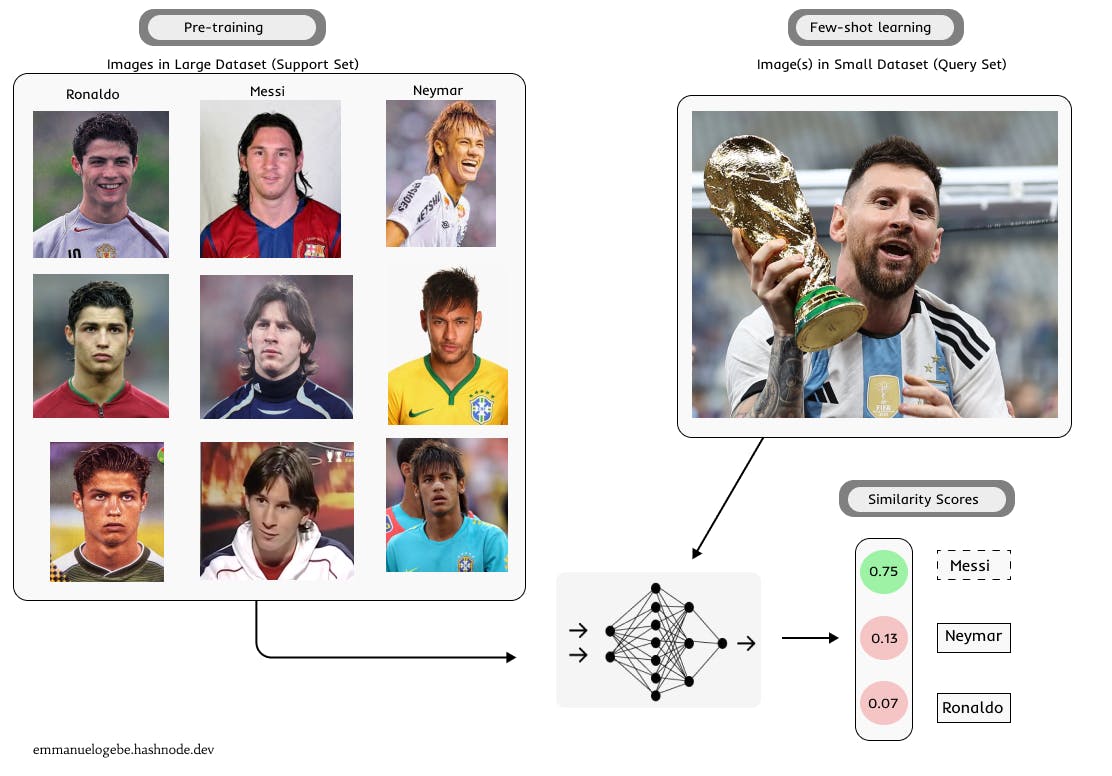
Illustration of the few-shot learning prediction process: the model has been trained with old images of footballers (Ronaldo, Messi, and Neymar). The model is now presented with a recent image of Messi that it has not seen before to make a prediction. [image by author]
Fine-tuning method: In this framework, the generalized knowledge of the pre-trained model is optimized to function in specialized tasks. This is done by additionally training the model on smaller task-specific datasets which will adjust the weights towards achieving optimum performance in the required functions. Fine-tuning mostly depends on the transfer learning approach for its operations.
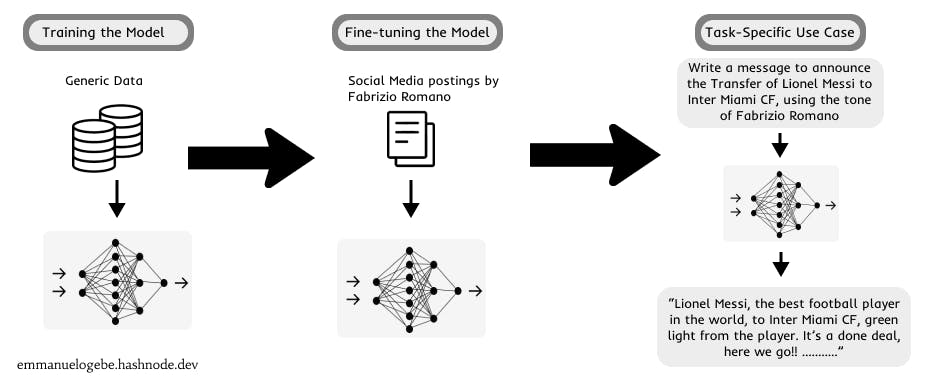
Illustration of a task-specific use case of a finetuned large language model: generating an announcement message on the transfer of Lionel Messi to Inter Miami CF in the likeness of Italian Football Journalist, Fabrizio Romano. [image by author]
What are the types of Large Language Models?
Although large language models intersect and interact depending on use cases and functionalities, they can broadly be grouped into three types - foundation models, fine-tuned models, and multimodal models.
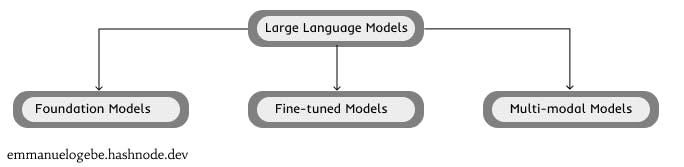
categories of large language models [image by author]
Foundation Models: These are out-of-the-box(OOTB) pre-trained models. These models can, later on, be optimized/upgraded for specific functions. Examples include GPT-3, BERT, and BLOOM.
Fine-tuned Models: These models have been fine-tuned for satisfactory performance in task-specific functions such as sentiment analysis, content creation, text classification, etc. Examples include ALBERT and T-NLG.
Multi-modal Models: These are powerful language models that understand the relationships between text, pictures, and sound. They can generate pictures, sounds, and videos from textual descriptions or vice versa. Examples include GPT-4, DALL-E 2, Imagen, AudioLM, CLIP, and Phenaki.
LLMs also differ in the way they process input and output data. There are different architectures for this: Encoder-only, Encoder-Decoder, and Decoder-only.
Encoder-only models only have an encoder, which takes in a data sequence and produces a representation of that data. This representation can then be used for different tasks including text classification and sentiment analysis.
Encoder-Decoder models have both an encoder and a decoder. The encoder takes in a data sequence and generates a representation of that data. The decoder then takes this representation and produces the desired output as a new data sequence. This architecture is often used for tasks that involve translating between languages or summarizing text.
Decoder-only models only have a decoder. The decoder takes in a data sequence and produces a new data sequence. This architecture is often used for tasks that require text generation, mostly with chatbots.
Examples of Large Language Models
Numerous examples of LLMs have been developed, with some publicly available to the public and others for internal use. Some of the largest language models according to parameter sizes, publicly known include:
| Model Name | Developer | Parameter Size |
| WuDao 2.0 | Beijing Academy of Artificial Intelligence | 1.75 trillion |
| Switch Transformer | Google AI | 1.6 trillion |
| PaLM 2 | Google AI | 540 billion |
| Megatron-Turing NLG | Microsoft and NVIDIA | 530 billion |
| Yuan 1.0 | Inspur AI Research | 245.7 billion |
| Jurassic-1 | A121 Labs | 178 billion |
| BLOOM | Hugging Face and others | 176 billion |
| GPT-3 | Open AI | 175 billion |
| OPT-IML | Meta AI | 175 billion |
| LaMDA | Google AI | 137 billion |
More models, larger than ever before, are still in development, for solving more complex problems. This development of large language models and AI tools built on top of them has been accelerating since the introduction of transformers by Google in 2017. Innovation in training techniques and the increasing availability of computational resources has also contributed greatly to the growth of LLMs.
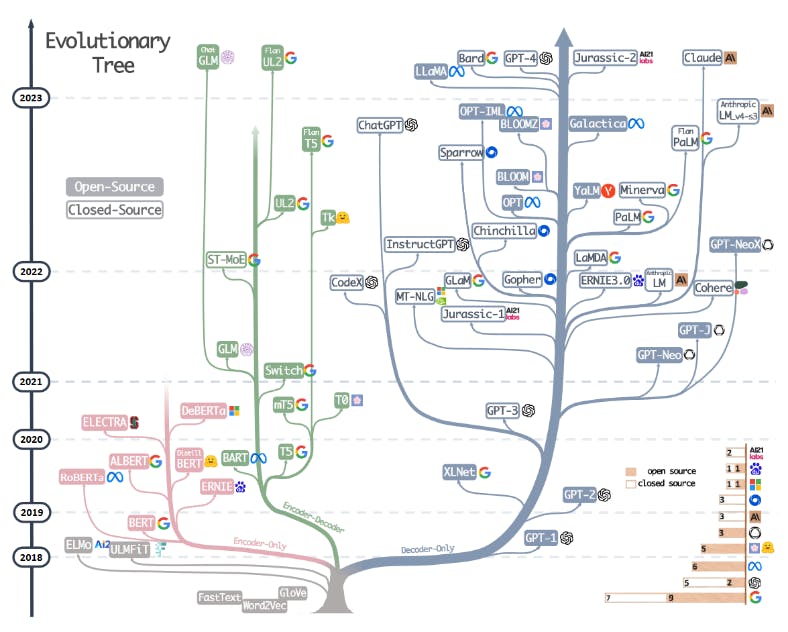
This illustration of the evolution of LLMs highlights some of the most well-known models and tools. [Image source "Harnessing the Power of LLMs in Practice"]
Applications of Large Language Models
There are many applications and possibilities with large language models, including but not limited to:
Text/Image/Sound Generation: Generating new forms of text, images, or sounds.
Sentiment Analysis: Deducing the opinions, rhythm, and moods in texts.
Machine Translation: Translating expressions from one language to another.
Question-Answering: Simulating human-like dialogued conversations.
Contextual Extraction: Pulling specific information and summarization from text sources.
Information Analytics: Generating analytics on information: word/character count, linguistic style usage, etc.
However, accessing these features for public usage is not directly possible as LLMs are very large and unable to run on a single computer. They can only be utilized via APIs and web interfaces such as chatbots and content generators eg ChatGPT, Bard, Bing Chat, etc
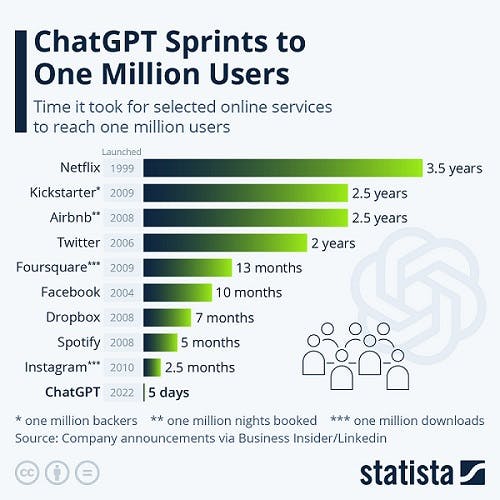
The time it took select online services to reach one million internet users. [Image source "ChatGPT Sprints to One Million Users"]
These web interfaces, especially ChatGPT - the fastest-growing consumer app in world history, have been the major sources of global interest and admiration for the capabilities of LLMs.
Challenges of Large Language Models
Similar to all technological advancements, the reception of large language models has also been met with criticism and challenges regarding their risks and dangers in different areas.
Cost-Intensive: LLMs are extremely expensive and technically challenging to train, with studies indicating upwards of 1.6 million USD per 1.5 billion data parameters trained. Although these costs are expected to come down, LLM training is currently only possible by major technology companies and Governments. This poses great challenges for the global democratization of LLMs, as those who can invest in its development could do so to the detriment of others.
Ethical Issues: Sensitive information in the data used to train LLMs could lead to security breaches and constitute risky situations for individuals, societies, groups, and Governments. Furthermore, the information generated in response to prompts is occasionally incorrect and cannot be depended on for critical use cases eg health information, journalism, etc.
Bias: The fact that LLMs are trained on the most publicly accessible data sources is a guaranteed hotbed for bias. This is because the people who put information on the internet, do so with their own biases, leanings, beliefs, and identifications. LLMs could then learn from and make categorical expressions with these biases in political, gender, racial, socio-economic, and other forms. GPT-3 through ChatGPT has indicated clear disparities in its assessment of Donald Trump as opposed to Joe Biden.
Societal Concerns: LLMs could be engineered for mass propaganda campaigns toward changing public perception and discourse on certain issues. They could also be used to send destructive information to companies that depend on them for activities such as code generation and other forms of generated content.
Deep Fakes: Exact human-like expressions of people, stories, and events are being digitally created in picture, video, and audio formats with malicious intents of spreading falsehoods and misinformation. The development of LLMs has made these deep fakes easier to make, harder to spot, and nearly impossible to regulate. This is increasingly dangerous for politicians, high net-worth individuals, and organizations in critical sectors.
Carbon Footprints: Training a large language model requires enormous usage of computational power. This means exhaustive energy utilization will be increasingly required in training LLMs, thus increasing carbon emissions.
Model Collapse: As LLMs get increasingly trained on large amounts of data parameters, a situation could arise where there is no more information on publicly available sources for them to learn from. Termed "model collapse"(a threat similar to catastrophic forgetting and data poisoning) by researchers is a dangerous degenerative possibility of language models learning from AI-generated data and straying further away from reality, which reinforces falsehoods.
What is the future of Large Language Models?
This is an exciting period of technological advancement as large language models are here to stay. There is hope that some of the challenges they pose will be reduced in the years to come.
LLMs are assistive tools to help everyone to be more efficient and make better decisions while carrying out their activities. They will impact and drive new possibilities in healthcare delivery, education, financial services, security, and lots more.
The long-prophesized era of the 5th industrial revolution (Industry 5.0), featuring the harmonious collaboration between humans and machines powered by automation, quantum computing, and artificial intelligence, is now a step closer to its realization.
Notes From the Author:
This article has been a deep dive into large language models. I truly hope you have been able to understand what LLMs are about or learned something new about their capabilities. I used Figma tools to design some images for easy and relatable understanding. These images are free to use by anyone interested in sharing more knowledge about LLMs, here is a link to the Figma file. I would appreciate comments, questions, and rectifications regarding this article.
Please feel free to connect with me on LinkedIn and interact with me on Twitter.
If this article has been beneficial to you, I would really appreciate it if you could Buy Me a Coffee to show some support as I continue to delve into more exciting technology topics. "Good things happen over coffee"