
Nigerian Movie Recommendation System: A Machine Learning Project
Insights on a Movie Recommendation System for Nigerian Movies


Abstract
Nollywood
movies are referred to as “Nollywood” because they were produced in Nigeria utilizing a type of video equipment known as a “Nolly,” which was thought to be an acronym for “Nigeria” or “National Optical Lens.”
The Nigerian Movie Industry popularly referred to as Nollywood is the largest movie industry globally in terms of output, and is the third largest, in terms of overall revenues generated. It is one of Africa's greatest achievements and is its most prolific film industry.
Movie Recommendation System
A movie recommendation system seeks to determine movie content that would be of interest to an individual. It utilizes machine learning to filter or predict the users’ film preferences based on their behaviour or past choices. There are two main types of movie recommender systems: Content-Based Filtering and Collaborative Filtering.
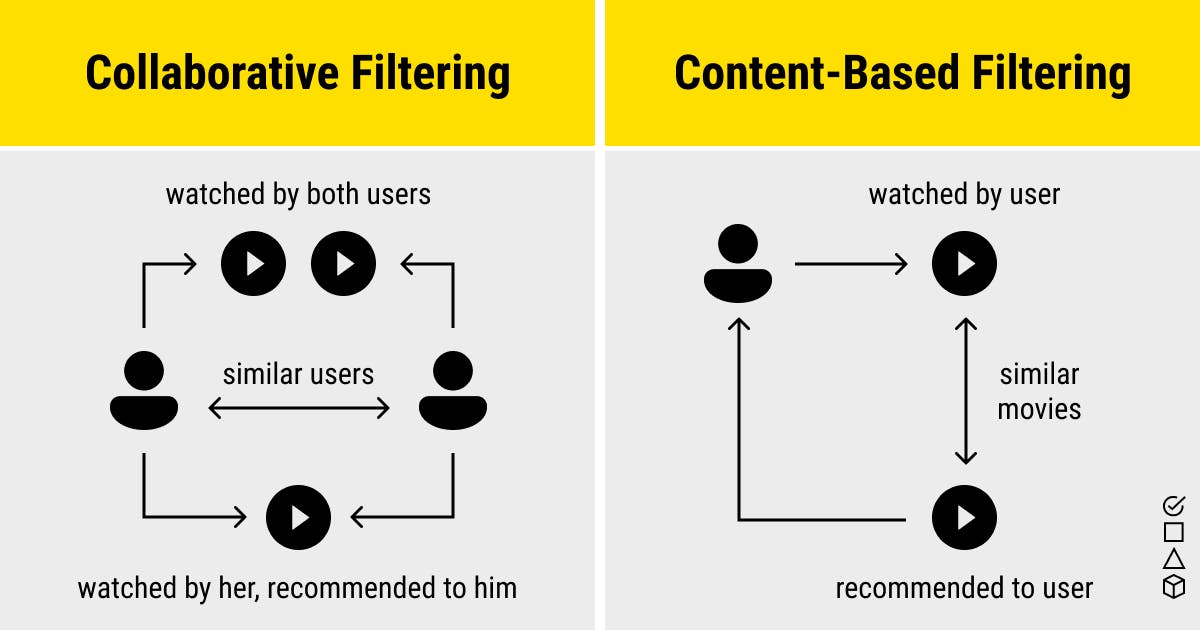
Image sourced from labelyourdata.com
Content-Based Movie Recommendation System
Collaborative Movie Recommendation System
Description
I have always enjoyed Nigerian movies and series. Recently, I thought about how I could help myself and others interested in Nigerian movies to get recommendations on movies to watch based on a movie they liked and had previously watched.
Of course, the way to do this would be to create accounts on the numerous movie streaming sites that post Nigerian content, indigenous Iroko TV, Netflix, Amazon Prime, etc, and search there, but they can only recommend movies within their catalogue. Another way would be to make Google searches. While Google searches are extremely efficient, they might not immediately yield desired results due to the indexing and ranking criteria.
I decided to build a Nigerian movie recommendation system, getting data from the Internet Movie Database (IMDb), the largest online database of movie-related information.
This recommendation system is content-based: utilising attributes like the cast, director, synopsis, genre, movie title, etc. It works with the assumption that if a user likes a particular movie, then similar movies would also be of interest.
Procedure
In building the recommendation system, I selected my finest weapons of choice, which have never failed nor forsaken me, Python, R and Google Colab. I decided that the web scraping of Nigerian Movies on IMDb will be done using R's rvest package and the recommendation system will be built mainly using Python's scikit-learn library. For the overall visibility of the project, and because I can, I chose to write my Python and R codes in the same notebook.
Process
Web Scraping the IMDb Website using R
I initialized the rpy2 package to simultaneously use R and Python in the same notebook
!pip install rpy2==3.5.1
%load_ext rpy2.ipython
then I installed the required R packages
%%R
suppressWarnings(suppressPackageStartupMessages({
install.packages("rvest")
install.packages("tidyverse")
install.packages("purrr")
install.packages('skimr')
install.packages('stringr')
install.packages('openxlsx')
}))
suppressWarnings(suppressPackageStartupMessages({
library(rvest)
library(tidyverse)
library(purrr)
library(skimr)
library(stringr)
library(openxlsx)
}))
I considered the time and resources required and decided at this stage to extract the details of the top 5000 Nigerian movies ordered by popularity on IMDb. Due to the structure of the IMDb site, it would have been a cumbersome task to scrape all movie details in a single query. Therefore, I had to break it down, scraping the titles, year, genre, certificate, rating and synopsis of the 5000 movies first and then scraping the cast and directors in chunks of 1000 per query. It was particularly rewarding that I used Google Colab; I had access to Google Cloud's TPU hardware accelerator which significantly sped up the process, if not, my Laptop PC could have caught on fire, in utilising its local resources for this.
scraping the titles, year, genre, certificate, rating and synopsis of the 5000 movies
%%R
movies1 = data.frame()
for(page_result in seq(from = 1, to = 4951, by = 50)){
link = paste0("https://www.imdb.com/search/title/?country_of_origin=NG&start=", page_result, "&ref_=adv_nxt")
page <- read_html(link)
df <- page %>%
html_nodes(".mode-advanced") %>%
map_df(~list(title = html_nodes(.x, '.lister-item-header a') %>%
html_text() %>%
{if(length(.) == 0) NA else .},
year = html_nodes(.x, '.text-muted.unbold') %>%
html_text() %>%
{if(length(.) == 0) NA else .},
genre = html_nodes(.x, '.genre') %>%
html_text() %>%
{if(length(.) == 0) NA else .},
certificate = html_nodes(.x, '.certificate') %>%
html_text() %>%
{if(length(.) == 0) NA else .},
rating = html_nodes(.x, '.ratings-imdb-rating strong') %>%
html_text() %>%
{if(length(.) == 0) NA else .},
synopsis = html_nodes(.x, '.ratings-bar+ .text-muted') %>%
html_text() %>%
{if(length(.) == 0) NA else .}))
movies1 = rbind(movies1, df)
print(paste("Page:", page_result))
}
scraping the cast and directors per 1000 movies, I repeated this code 5 times, changing the sequence (page numbers) per query and storing it in new variables
%%R
#Cast and Directors for movies 1 - 1000
get_cast = function(movie_link) {
movie_page = read_html(movie_link)
cast = movie_page %>% html_nodes(".cast_list tr:not(:first-child) td:nth-child(2) a") %>% html_text() %>% paste(collapse = ",")
directors = movie_page %>% html_nodes("h4:contains('Directed by') + table a") %>% html_text() %>% paste(collapse = ",")
return(data.frame(cast = cast, directors = directors))
}
movies2 = data.frame()
for(page_result in seq(from = 1, to = 951, by = 50)){
link = paste0("https://imdb.com/search/title/?country_of_origin=NG&start=", page_result, "&ref_=adv_nxt")
page <- read_html(link)
movie_links = page %>% html_nodes(".lister-item-header a") %>% html_attr("href") %>% str_replace(pattern = fixed("?ref_=adv_li_tt"), replacement = fixed("fullcredits/?ref_=tt_cl_sm")) %>%
paste("http://www.imdb.com", ., sep="")
movie_data = lapply(movie_links, get_cast)
df = bind_rows(movie_data)
movies2 = rbind(movies2, df)
print(paste("Page:", page_result))
}
the next step was to make copies and merge the data frames together into a singular data frame and clean it to remove unwanted elements
merging the data frames
%%R
movies2_copy <- movies2
movies3_copy <- movies3
movies4_copy <- movies4
movies5_copy <- movies5
movies6_copy <- movies6
movies2_copy = rbind(movies2_copy, movies3_copy)
movies2_copy = rbind(movies2_copy, movies4_copy)
movies2_copy = rbind(movies2_copy, movies5_copy)
movies2_copy = rbind(movies2_copy, movies6_copy)
movies_copy = cbind(movies1_copy, movies2_copy)
movies_copy1 <- movies_copy
data cleaning and writing to Excel (this was necessary as I needed to do additional pre-processing on the data in MSExcel)
%%R
movies_copy1$genre <- gsub("\n", "", movies_copy1$genre)
movies_copy1$genre <- gsub(",", "", movies_copy1$genre)
movies_copy1$cast <- gsub("\n", "", movies_copy1$cast)
movies_copy1$cast <- gsub(",", "", movies_copy1$cast)
movies_copy1$directors <- gsub("\n", "", movies_copy1$directors)
movies_copy1$directors <- gsub(",", "", movies_copy1$directors)
movies_copy1$synopsis <- gsub("\n", "", movies_copy1$synopsis)
write.xlsx(movies_copy1, "movies_copy1.xlsx")
The cleaned dataset is publicly available for use here.
Building the Recommendation System using Python
In building this recommendation system for Nigerian movies, my sentiments are that in terms of preference, many Nigerians watch movies mainly because of the actors and sometimes directors, due to their "star power" and then the genre and synopsis. I will be using these unique features to build the recommendation system.
importing Python libraries and dependencies
import pandas as pd
import numpy as np
import difflib
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
loading the data
movies_data = pd.read_excel("/content/movies_copy1.xlsx")
building the model
#selecting the unique features, replacing the null values with null string and combining all unique features per movie
unique_features = ['cast','directors','genre','synopsis']
for feature in unique_features:
movies_data[feature] = movies_data[feature].fillna('')
combined_features = movies_data['cast'] +' '+ movies_data['directors'] +' '+ movies_data['genre'] +' '+ movies_data['synopsis']
I needed to convert the combined features by fitting and transforming them into a numerical representation using the TfidVectorizer, this was to enable me to obtain the cosine similarity scores as text data is not appropriate for machine learning modelling, after which, I could determine their similarity scores.
feature_vectors = TfidfVectorizer().fit_transform(combined_features)
similarity = cosine_similarity(feature_vectors)
setting the parameters
I structured the system to accept input (movie name) from a user, and the closest match from the movies list will be selected (the closest match is to cover for spelling errors and minor mistakes when giving input). The similarity score of the closest match will be compared with the similarity scores of every movie in the dataset and a list of movies will be generated ordered by highest similarity, and the top 20 movies will then be recommended to the user.
accepting input of a favourite movie and finding close matches to it
#creating a list with all the movie names
list_of_all_titles = movies_data['movie_title'].to_list()
#accepting input from the user
movie_name = input('Enter your favourite movie name : ')
#finding the close matches to the movie input and select the closest match, the similarity cutoff was readjusted from the default 0.6 to 0.5, because some movie titles have numbers and special characters attached to it
find_close_match = difflib.get_close_matches(word = movie_name, possibilities = list_of_all_titles, n = 5, cutoff = 0.5)
close_match = find_close_match[0]
next steps..
#obtaining the index of the close match
index_of_the_movie = movies_data[movies_data.movie_title == close_match]['index'].values[0]
#listing the indexes and similarity scores of all movies in the dataset with the closest match
similarity_score = list(enumerate(similarity[index_of_the_movie]))
#sorting the movies based on their similarity score
sorted_similar_movies = sorted(similarity_score, key = lambda x:x[1])
printing similar movies..
# Displaying the top 20 with the highest similarity scores to the searched item
print('Recommended Movies : \n')
i = 1
for movie in (sorted_similar_movies):
index = movie[0]
title_from_index = movies_data[movies_data.index==index]['movie_title'].values[0]
if (i<21):
print(i, '.',title_from_index)
i+=1
putting it all together
movie_name = input('Enter your favourite movie name : ')
list_of_all_titles = movies_data['movie_title'].to_list()
find_close_match = difflib.get_close_matches(word = movie_name, possibilities = list_of_all_titles, n = 5, cutoff = 0.5)
close_match = find_close_match[0]
similarity_score = list(enumerate(similarity[index_of_the_movie]))
sorted_similar_movies = sorted(similarity_score, key = lambda x:x[1])
print('Recommended Movies : \n')
i = 1
for movie in sorted_similar_movies:
index = movie[0]
title_from_index = movies_data[movies_data.index==index]['movie_title'].values[0]
if (i<21):
print(i, '.',title_from_index)
i+=1
The recommendation system is complete. This is a snippet of the results when I ran it.
Conclusion and Next Steps
Conclusion:
The recommendation system is working very well as it should.
As an avid lover of Nigerian movies, I can personally confirm that most of the recommended movies are movies I will enjoy if I like the searched movies "Wedding Party", "Amina", "King of Boys", and "Chief Daddy". I have actually watched many of the movies that were populated on the lists.
Challenges:
I would have loved to have a more holistic dataset with more attributes, eg short notes on the movies instead of the synopsis and movie tags in addition to the genre.
Nigerian movie producers tend to fuse elements of Drama, Comedy and Romance into most movies. This poses a problem for the recommendation system, as a user who searches for Drama could also get Comedy results as well and it would be impossible to dissociate a genre from a particular movie.
I observed that some music videos are also listed on the IMDb website as movies. I wasn't aware of this and will holistically dig into the dataset during the next cleaning process to remove them.
Next Steps:
This was just the testing phase. In the next development stage, I am looking to scrape the data of all 12,667 Nigerian movie titles (as of April 19, 2023) on IMDb.
There is a need to include the year of movie release in the unique features, this is because a person might not necessarily enjoy movies with extremely varying release years. eg a person might not enjoy a 1994 movie even if has the same genre and somewhat similar synopsis as a 2014 movie.
I will explore other available methods for building a much more refined and highly accurate content-based movie recommendation system.
I need to utilise a web server to deploy the recommendation system to production. This will make it available for everyone to use, and give necessary comments or feedback.
The Google Colab notebook of this movie recommendation system is available here. It is also available on my Kaggle and GitHub.
You can connect with me on LinkedIn and interact with me on Twitter.
Footnotes
Special appreciation to Governor Ajanaku, who assisted me with a little issue I had during the web scraping.
R Packages Explanation: I used the rvest and stringr packages to scrape data from the IMDb pages and to manipulate some strings to support the web scraping. I used tidyverse and openxlsx for data manipulation and writing to Excel worksheets, and the skimr and purrr packages enabled me to have comprehensive summary statistics of the data frames and map functions.
Python Libraries Explanation: I used pandas and numpy to read and manipulate the data, and difflib to compare the movie title input with all movie titles in the dataset. TfidfVectorizer and Cosine similarity from scikit-learn were used to transform texts into numerical representations and measure similarities between two items.